
Dataflow Gen2
Dataflow is a tool that has been around in the Power BI service for a very long time , and is used to import, transform, and load data into a semantic model (ETL). Practically, it is Power Query in a cloud environment. With the advent of Microsoft Fabric, Dataflow Gen2 was introduced , which is much more advanced compared to the previous version and enables faster work with large amounts of data, as well as their parallel processing.
Unlike the first version of Dataflow, which uses the Power BI engine, and stores data in the form of CSV files in the Azure Data Lake repository, Dataflow Gen2 uses Apache Spark in the Fabric environment, and saves tables in Delta Parquet format (versioned Parquet), in OneLake. Data can also be imported as Lakehouse, Warehouse, SQL DB, Kusto, etc.
Dataflow Gen2 is very easy to use. If you’ve ever worked with Power Query, you’ll quickly understand how it works. First, log in to the Power BI (Microsoft Fabric) service. Then, click on the Create button. A window will open that offers more ways to import data. Let’s choose the OneLake catalog.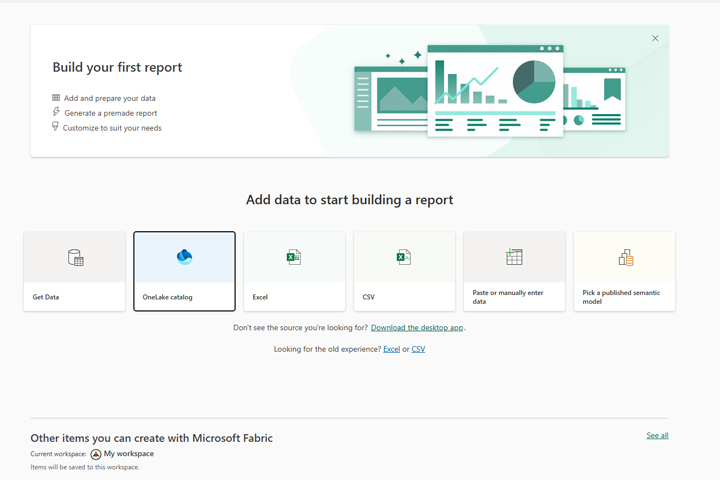
A window will open with the existing contents of the catalog. Click on Add Content. A new window will open that shows you the wealth of content you can create. Instead of the traditional model, we will create a lakehouse on this occasion. It is a modern data architecture that combines Data Lake (stores unstructured and semi-structured data) and Data Warehouse (scripted tables, suitable for reporting and analysis). The data is stored in Delta Parquet tables, and it is possible to access and extract the data necessary for reporting later using PySpark (Python in the Apache environment) or SQL.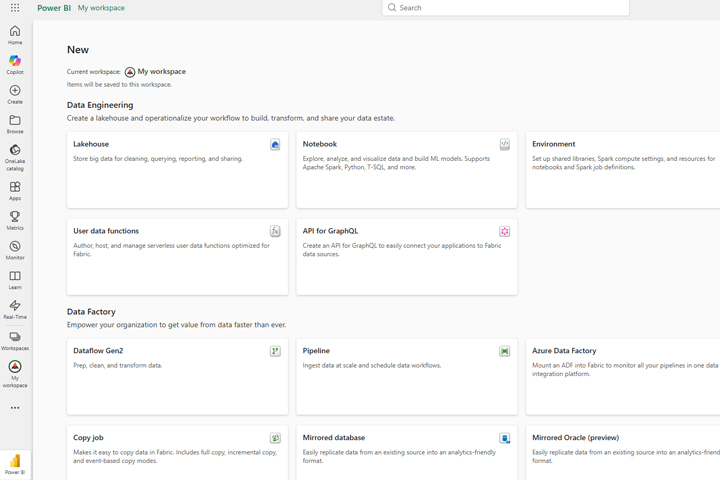
A window will open to create a new Lakehouse, where we will give it an arbitrary name.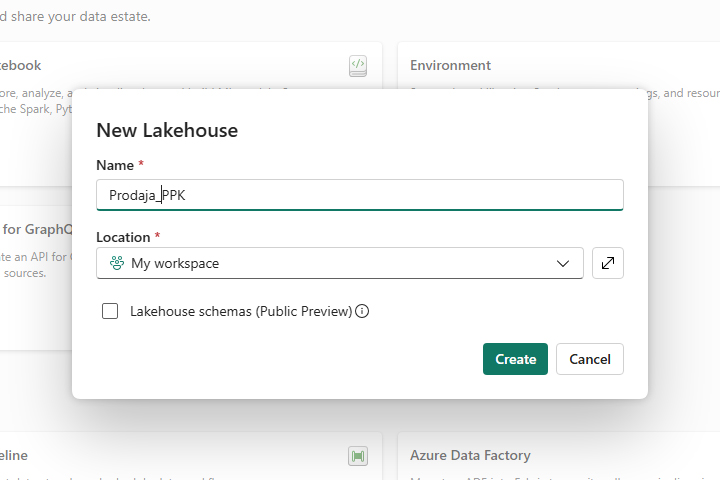
Once you’ve created a Lakehouse, you’ll see its name, and within it two folders: Tables and Files. The Files folder stores unstructured and semi-structured files, and the Tables folder contains tables that we will use for reporting and analysis. In parallel with the creation of the Lakehouse, a SQL Analytics Endpoint is automatically created , which is used to, if you wish, extract data using SQL queries.
Open the Get Data menu, and then select Dataflow Gen2 to import the data. When the window opens, we’ll give it a suitable name, and then choose where we want to import the data from: from an Excel file, a CSV file, SQL server, an existing Dataflow, or some other source. In this example, we’re importing data from an Excel file.
Next, an import window will appear, similar to the one in Power Query, where you need to select one or more tables that you want to import.
Finally, the result of the import is stored in an environment that resembles Power Query Editor. Here it is possible to further perform data transformations until we are satisfied with its appearance.

We can eventually add the transformed tables to the desired Lakehouse and continue to store them there and use them to create Power BI reports.